

Edited: this post to be the Lemmy.World federation issue post.
We are now ready to upgrade to postgres 16. When this post is 30 mins old the maintenace will start
Updated & Pinned a Comment in this thread explaining my complete investigation and ideas on how the Lemmy app will & could move forward.
LemmyWorld -> Reddthat
What if I told you the problems LW -> Reddthat have is due to being geographically distant on a scale of 14000km?
Problem: Activities are sequential but requires external data to be validated/queried that doesn’t come with the request. Server B -> A, says here is an activity. In that request can be a like/comment/new post. An example of a new post would mean that Server A, to show the post metadata (such as subtitle, or image) queries the new post.
Every one of these outbound requests that the receiving server does are:
- Sequential, (every request must happen in order: 1,2,3,4…
- Is blocking. Server B which sent a message to server A, must wait for Server A to say “I’m Finished” before sending the next item in queue.
- Are inherently subsequent to network latency (20ms to 600ms)
- Australia to NL is 278ms
- NL to LA is 145ms
- I picked NL because it is geographically, and literally, on the other side of the world from Australia. This is (one of) if not the longest route between two lemmy servers.
Actual Problem
So every activity that results in a remote fetch delays activities. If the total activities that results in more than 1 per 0.6s, servers physically cannot and will never be able to catch up. As such our decentralised solution to a problem requires a low-latency solution. Without intervention this will evidently ensure that every server will need to exist in only one region. EU or NA or APAC (etc.) (or nothing will exist in APAC, and it will make me sad) To combat this solution we need to streamline activities and how lemmy handles them.
A Possible Solution?
Batching, parallel sending, &/or moving all outbound connections to not be blocking items. Any solution here results in a big enough change to the Lemmy application in a deep level. Whatever happens, I doubt a fix will come super fast
Relevant traces to show network related issues, for those that are interested
Trace 1:
Lemmy has to verify a user (is valid?). So it connects to a their server for information. AU -> X (0.6) + time for server to respond = 2.28s but that is all that happened.
- 2.28s receive:verify:verify_person_in_community: activitypub_federation::fetch: Fetching remote object http://server-c/u/user - request completes and closed connectionTrace 2:
Similar to the previous trace, but after it verfied the user, it then had to do another
from_jsonrequest to the instance itself. (No caching here?) As you can see 0.74 ends up being the server on the other end responding in a super fast fashion (0.14s) but the handshake + travel time eats up the rest.- 2.58s receive:verify:verify_person_in_community: activitypub_federation::fetch: Fetching remote object http://server-b/u/user - 0.74s receive:verify:verify_person_in_community:from_json: activitypub_federation::fetch: Fetching remote object http://server-b/ - request continuesTrace 3:
Fetching external content. I’ve seen external servers take upwards of 10 seconds to report data, especially because whenever a fediverse link is shared, every server refreshes it’s own data. As such you basically create a mini-dos when you post something.
- inside a request already - 4.27s receive:receive:from_json:fetch_site_data:fetch_site_metadata: lemmy_api_common::request: Fetching site metadata for url: https://example-tech-news-site/bitcoin-is-crashing-sell-sell-sell-yes-im-making-a-joke-here-but-its-still-a-serious-issue-lemmy-that-is-not-bitcoinTrace 4:
Sometimes a lemmy server takes a while to respond for comments.
- 1.70s receive:community: activitypub_federation::fetch: Fetching remote object http://server-g/comment/09988776Notes:
[1] - Metrics were gathered by using https://github.com/LemmyNet/lemmy/compare/main...sunaurus:lemmy:extra_logging patch. and getting the data between two logging events. These numbers may be off by 0.01 as I rounded them for brevity sake.
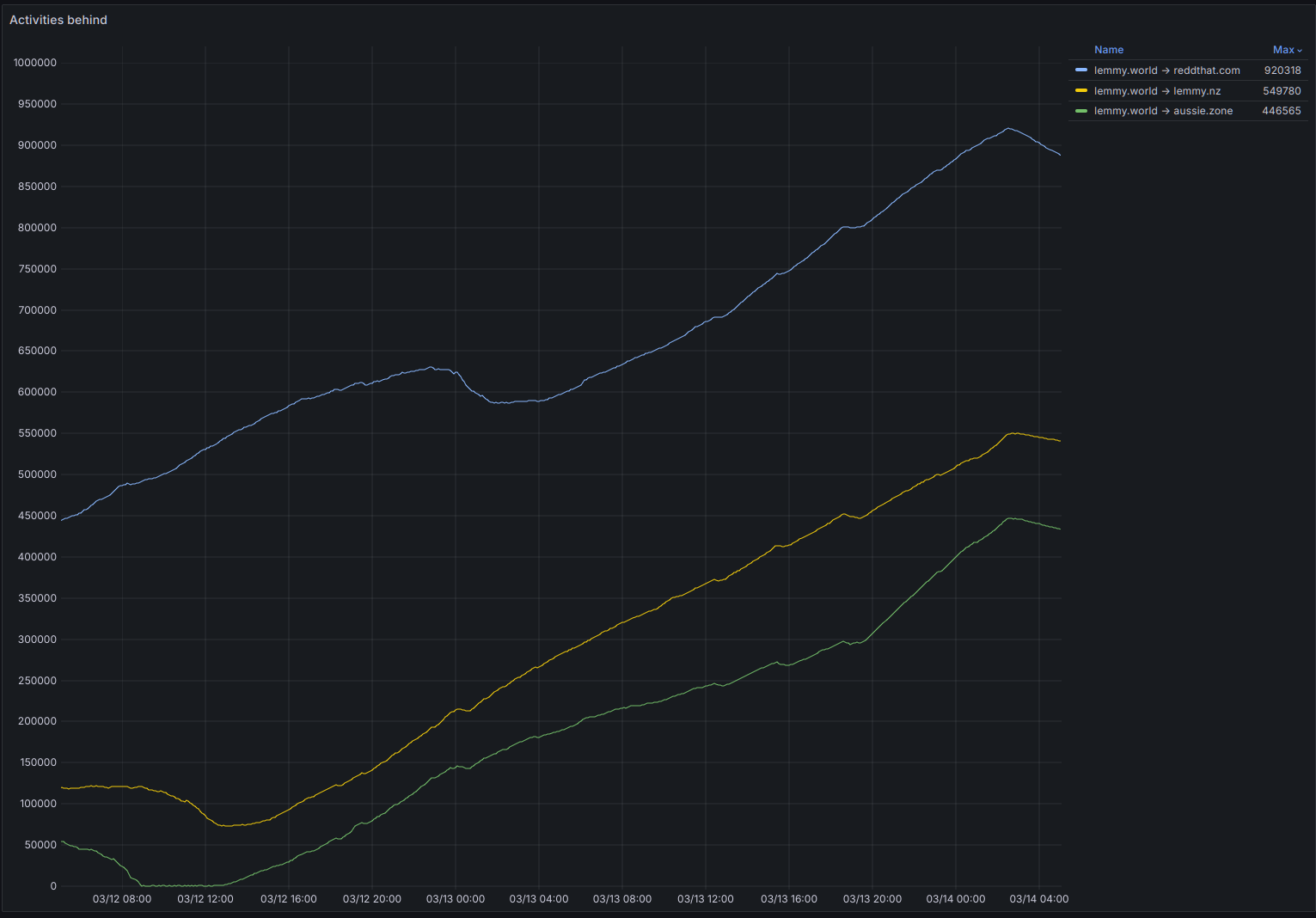
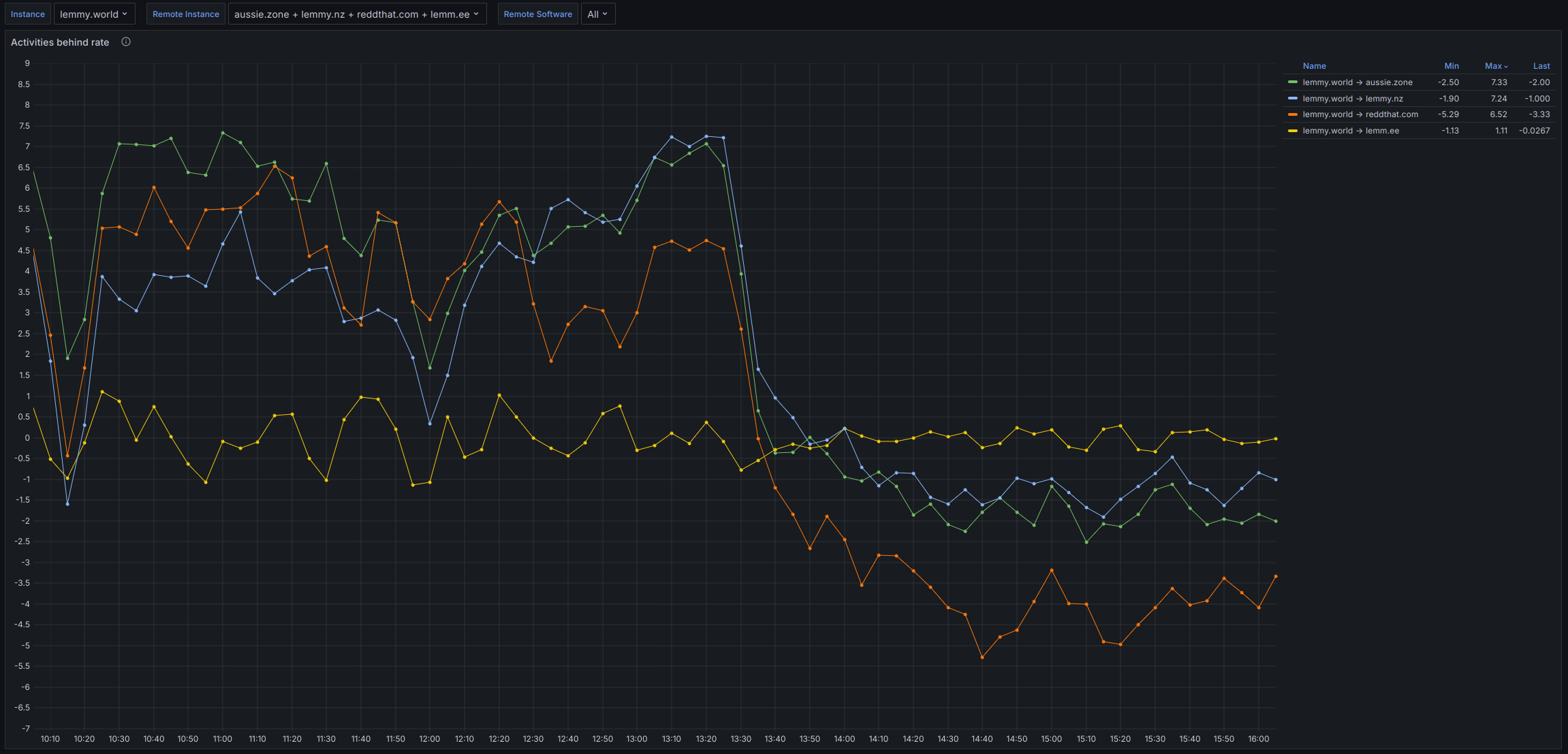
Relevant Pictures!
How far behind we are now:

The rate at which activities are falling behind (positive) or if we are catching up (negative)

I thought Lemmy supported horizontal scaling for federation activities.
Wondering how many instances of the federation server reddthat is running and if increasing the number does anything for the issue.
Edit: It seems that 0.19 started synchronizating activities, so horizontal scaling is out of the question.
It does. But only outbound. So we have 2 containers for federating outbound. It splits the list of servers in 2. Then each process sends out the queries. This is good for when you have a lot of servers federating with you.
But currently when accepting activities from 1 instance it is only 1 thread and it is only sequential/chronological order.
Just FYI, I have suggested to the moderation team of [email protected] to consider moving the community to another instance so that you guys can still participate.
The technical issue might still be there, but I guess that can be a way to avoid overworking LW
Thank you so much for the detailed answer!
This could be it!
Successfully migrated from Postgres 15 to Postgres 16 without issues.
Well done!
Interestingly enough, the number keep growing 😔
https://phiresky.github.io/lemmy-federation-state/site?domain=lemmy.world
Yes… it is VERY annoying. We have so much resources available and lemmy/postgres will not use them

That’s sad.
I’ve seen you posted in the Lemmy Matrix channel, hopefully you’ll be able to find a way soon. I guess you already read the write-up from Db0? https://dbzer0.com/blog/post-mortem-the-massive-lemmy-world-lemmy-dbzer0-com-federation-delays/
Yes. Unfortunately the information gleamed boils down to two reasons:
- their db was slow to respond
- their db server ended up being 25ms away from their backend servers which caused the slowness.
Our db server is occasionally slow to respond, but most requests from LW complete in less than 0.1 second. Unfortunately there are times when they take longer. These longer ones are going to be the problem (I believe). As all activities are sequential servers can only catch up as fast as they can process them.
What i’ve found in the past 30 seconds is that it is not necessarily out database that is the problem but possibly the way lemmy handles the federation. I’m chatting with some of the admins on reddthat and making pretty graphs while looking at walls of logs.
I see, thank you for your work!
I was right https://reddthat.com/comment/8316861
reddthat.com is also having problems with lemmy.today
No we aren’t…are we? Both servers report being up-to-date with each other.
https://phiresky.github.io/lemmy-federation-state/site?domain=Lemmy.today
https://phiresky.github.io/lemmy-federation-state/site?domain=reddthat.com
Seems pretty good to me:
- https://grafana.lem.rocks/d/edf3gjrxxnocgd/federation-health?orgId=1&var-instance=lemmy.today&var-remote_instance=reddthat.com&var-remote_software=All
- https://grafana.lem.rocks/d/edf3gjrxxnocgd/federation-health?orgId=1&var-instance=reddthat.com&var-remote_instance=lemmy.today&var-remote_software=All
Yes we are some of the post history community etc from lemmy today are missing when looking reddthat
Can you share an example?
What kind ? Screenshots or written ?
To investigate we need the links to the posts or communities that are apparently syncing behind. From LemmyToday and Reddthat.
Also if you create a new community on LemmyToday then it won’t automatically appear under /all unless you tell remote servers about it.
You need at least 1 user on Reddthat to subscribe to the community for it to start syncing. Once that is done it will sync. And as with the links Blaze & I have shown, you can see that as far as the currently known communities, we are all up-to-date.A good example of what we need to investigate is : https://reddthat.com/post/14961735


