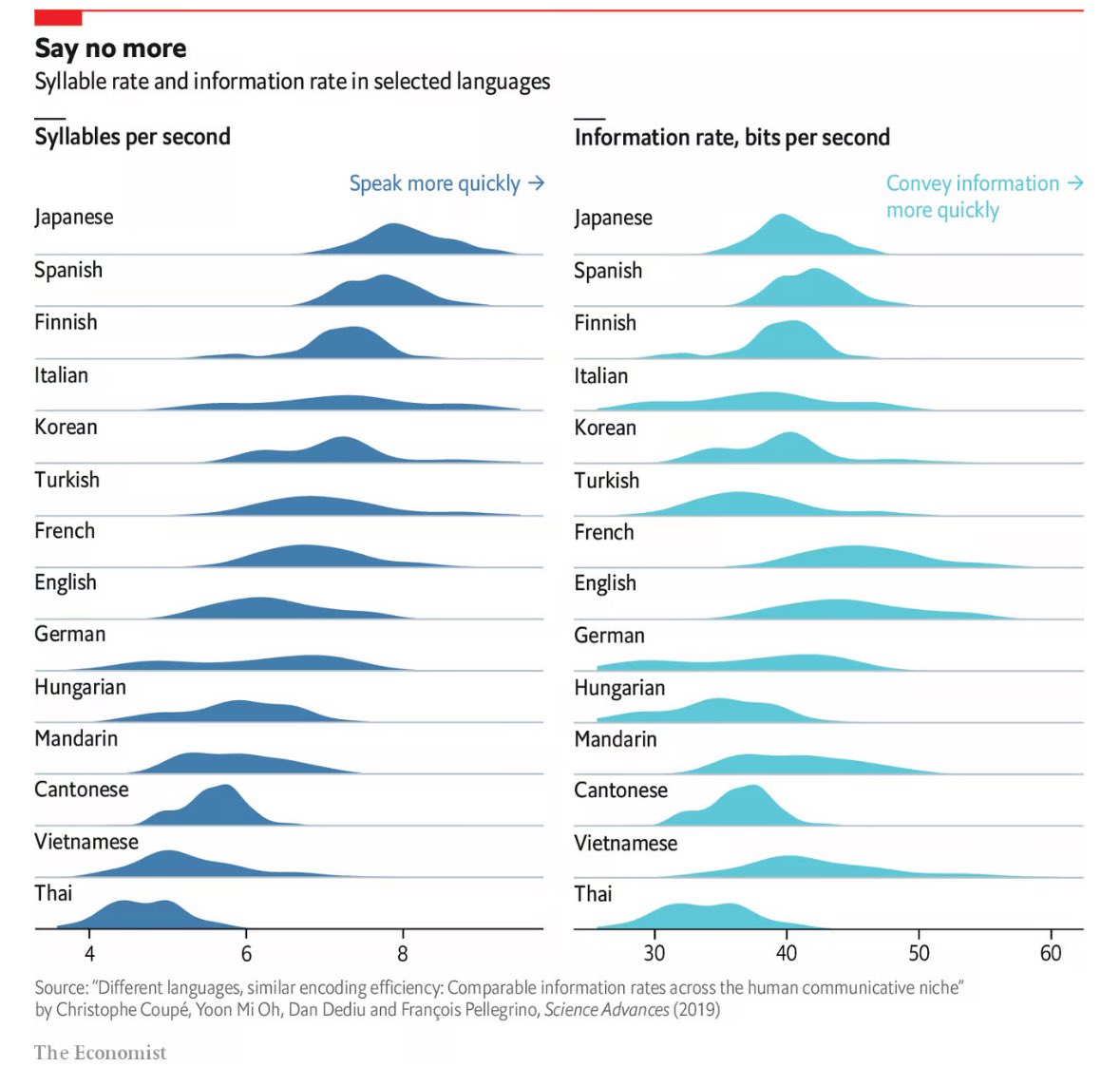
So I did a quick pass through the paper, and I think it’s more or less bullshit. To clarify, I think the general conclusion (different languages have similar information densities) is probably fine. But the specific bits/s numbers for each language are pretty much garbage/meaningless.
First of all, speech rates is measured in number of canonical syllables, which is a) unfair to non-syllabic languages (e.g. (arguably) Japanese), b) favours (in terms of speech rate) languages that omit syllables a lot. (like you won’t say “probably” in full, you would just say something like “prolly”, which still counts as 3 syllables according to this paper).
And the way they calculate bits of information is by counting syllable bigrams, which is just… dumb and ridiculous.
Alright, but dismissing the study as “pretty much bullshit" based on a quick read-through seems like a huge oversimplification. Using canonical syllables as a measure is actually a widely accepted linguistic standard, designed precisely to make fair comparisons across languages with different structures, including languages like Japanese. It’s not about unfairly favoring any language but creating a consistent baseline, especially when looking at large, cross-linguistic patterns.
And on the syllable omission point, like “probably” vs. “prolly," I mean, sure, informal speech varies, but the study is looking at overall trends in speech rate and information density, not individual shortcuts in casual conversation. Those small variations certainly don’t turn the broader findings into bullshit.
As for the bigram approach, it’s a reasonable proxy to capture information density. They’re not trying to recreate every phonological or grammatical nuance; that would be way beyond the scope and would lose sight of the larger picture. Bigrams offer a practical, statistically valid method for comparing across languages without having to delve into the specifics of every syllable sequence in each language.
This isn’t about counting every syllable perfectly but showing that despite vast linguistic diversity, there’s an overarching efficiency in how languages encode information. The study reflects that and uses perfectly acceptable methods to do so.
Well I did clarify I agree that the overarching point of this paper is probably fine…
widely accepted linguistic standard
I am not a linguist so apologise for my ignorance about how things are usually done. (Also, thanks for educating me.) But on the other hand just because it is the accepted way doesn’t mean it is right in this case. Especially when you consider the information rate is also calculated from syllables.
syllable bigrams
Ultimately this just measures how quickly the speaker can produce different combinations of sounds, which is definitely not what most people would envision when they hear “information in language”. For linguists who are familiar with the methodology, this might be useful data. But the general public will just get the wrong idea and make baseless generalisations - as evidenced by comments under this post. All in all, this is bad science communication.
But the general public will just get the wrong idea and make baseless generalisations - as evidenced by comments under this post. All in all, this is bad science communication.
Perhaps, but to be clear, that’s on The Economist, not the researchers or scholarship. Your criticisms are valid to point out, but they aren’t likely to be significant enough to change anything meaningful in the final analysis. As far as the broad conclusions of the paper, I think the visualization works fine.
What you’re asking for in terms of methods that will capture some of the granularity you reference would need to be a separate study. And that study would probably not be a corrective to this paper. Rather, it would serve to “color between the lines” that this study establishes.
This conjecture explains the results surprisingly well. If the original was written in French, which then got translated to English, which was then used as the basis of translation for the other languages that would explain the results entirely.

{kind=link}
I am pretty skeptical about these results in general. I would like to see the original research paper, but they usually
USwestern university campuses.And then there’s the question of how do you measure the amount of information conveyed in natural languages using bits…
Yeah, the results are mostly likely very skewed.
So I did a quick pass through the paper, and I think it’s more or less bullshit. To clarify, I think the general conclusion (different languages have similar information densities) is probably fine. But the specific bits/s numbers for each language are pretty much garbage/meaningless.
First of all, speech rates is measured in number of canonical syllables, which is a) unfair to non-syllabic languages (e.g. (arguably) Japanese), b) favours (in terms of speech rate) languages that omit syllables a lot. (like you won’t say “probably” in full, you would just say something like “prolly”, which still counts as 3 syllables according to this paper).
And the way they calculate bits of information is by counting syllable bigrams, which is just… dumb and ridiculous.
Alright, but dismissing the study as “pretty much bullshit" based on a quick read-through seems like a huge oversimplification. Using canonical syllables as a measure is actually a widely accepted linguistic standard, designed precisely to make fair comparisons across languages with different structures, including languages like Japanese. It’s not about unfairly favoring any language but creating a consistent baseline, especially when looking at large, cross-linguistic patterns.
And on the syllable omission point, like “probably” vs. “prolly," I mean, sure, informal speech varies, but the study is looking at overall trends in speech rate and information density, not individual shortcuts in casual conversation. Those small variations certainly don’t turn the broader findings into bullshit.
As for the bigram approach, it’s a reasonable proxy to capture information density. They’re not trying to recreate every phonological or grammatical nuance; that would be way beyond the scope and would lose sight of the larger picture. Bigrams offer a practical, statistically valid method for comparing across languages without having to delve into the specifics of every syllable sequence in each language.
This isn’t about counting every syllable perfectly but showing that despite vast linguistic diversity, there’s an overarching efficiency in how languages encode information. The study reflects that and uses perfectly acceptable methods to do so.
Well I did clarify I agree that the overarching point of this paper is probably fine…
I am not a linguist so apologise for my ignorance about how things are usually done. (Also, thanks for educating me.) But on the other hand just because it is the accepted way doesn’t mean it is right in this case. Especially when you consider the information rate is also calculated from syllables.
Ultimately this just measures how quickly the speaker can produce different combinations of sounds, which is definitely not what most people would envision when they hear “information in language”. For linguists who are familiar with the methodology, this might be useful data. But the general public will just get the wrong idea and make baseless generalisations - as evidenced by comments under this post. All in all, this is bad science communication.
Perhaps, but to be clear, that’s on The Economist, not the researchers or scholarship. Your criticisms are valid to point out, but they aren’t likely to be significant enough to change anything meaningful in the final analysis. As far as the broad conclusions of the paper, I think the visualization works fine.
What you’re asking for in terms of methods that will capture some of the granularity you reference would need to be a separate study. And that study would probably not be a corrective to this paper. Rather, it would serve to “color between the lines” that this study establishes.
I take your point without complaint, but I still think you’re an alien for saying “prolly”
I mean, probs. It’s right there. Use that if you have to
it’s pro^b - ly
This conjecture explains the results surprisingly well. If the original was written in French, which then got translated to English, which was then used as the basis of translation for the other languages that would explain the results entirely.
There’s always Google Scholar.