
Hi all, I have been chasing answers for this for months on the Proxmox forums, Reddit, and the LevelOneTechs forums and haven’t gotten much guidance, unfortunately. Hoping Lemmy will be the magic solution!
Perhaps I couched my initial thread in too much detail, so after some digging I got to more focused questions for my follow-up (effectively what this thread is), but I still didn’t get much of a response!
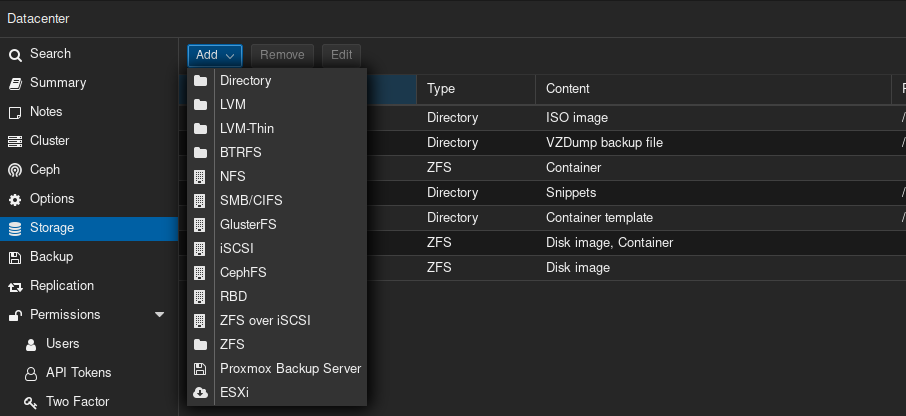
In all this time, I even have one more random thought I haven’t asked elsewhere - if I “Add Storage” of my ZFS pools in Proxmox, even though the categories don’t really fit data storage (the categories are like VM data, CT data, ISOs, snippets, etc.), then I could attach these to a VM or CT and replicate them via “normal” Proxmox cluster replication - is it OK to add such data pools to this storage section as such?
Anyway, to the main course - the summary of what I’m seeking help on is below.
Long story short:
- 3 nodes in a cluster, using ZFS.
- CTs and VMs are replicated across nodes via GUI.
- I want to replicate data in ZFS pools (which my CTs and VMs use - CTs through bind-mounts, VMs through NFS shares) to the other nodes.
- Currently using Sanoid/Syncoid to make this happen from one node to two others via cronjob.
So three questions:
- If I do Sanoid/Syncoid on all three nodes (to each other) - is this stupid, and will it fail - or will each node recognize snapshots for a ZFS pool and incrementally update if needed (even if the snapshot was made on/by a different node)?
- As a sub-question to this - and kind of the point of my overall thread and the previous one - is this even a sensible way to approach this, or is there a better way?
- For the GUI-based replication tasks, since I have CTs replicating to other systems, if I unchecked “skip replication” for the bind-mounted ZFS pools - would this accomplish the same thing? Or would it fail outright? I seem to remember needing to check this for some reason.
- Is this PVE-zsync suitable for my situation? I see mention of no recursive syncing, which I don’t fully know what that means, and I don’t know if that’s a dealbreaker. I suppose if this is the correct choice - then I need to delete my current GUI-based CT/VM replication tasks?
For those with immense patience, here was the original thread with more detail:
Hi all, so I setup three Proxmox servers (two identical, one “analogous”) - and the basics about the setup are as follows:
- VMs and CTs are replicated every 15 minutes from one node to the other two.
- One CT runs Cockpit for SMB shares - bind-mounted to the ZFS pools with the datasets that are SMB-shared.
- I use this for accessing folders via GUI over the network from my PC.
- One CT runs an NFS server (no special GUI, only CLI) - bind-mounted to the ZFS pools with the datasets that are NFS-shared (same as SMB-shared ones).
- Apps that need to tap into data use NFS shares (such as Jellyfin, Immich, Frigate) provided by this CT.
- Two VMs are of Debian, running Docker for my apps.
- VMs and CTs are all stored on 2x2TB M.2 NVMe SSDs.
- Data is stored in folders (per the NFS/SMB shares) on a 4x8TB ZFS pool with specific datasets like Media, Documents, etc. and a 1x4TB SSD ZFS “pool” for Frigate camera footage storage.
Due to having hardware passed-through to the VMs (GPU and Google Coral TPU) and using hardware resource mappings (one node as an Nvidia RTX A2000, two have Nvidia RTX 3050s - can have them all with the same mapped resource node ID to pass-through without issue despite being different GPUs), I don’t have instant HA failover.
Additionally, as I am using ZFS with data on all three separate nodes, I understand that I have a “gap” window in the event of HA where the data on one of the other nodes may not be all the way up-to-date if a failover occurs before a replication.
So after all the above - this brings me to my question - what is the best way to replicate data that is not a VM or a CT, but raw data stored on those ZFS pools for the SMB/NFS shares - from one node to another?
I have been using Sanoid/Syncoid installed on one node itself, with cronjobs. I’m sure I’m not using it perfectly (boy did I have a “fun” time with the config files), and I did have a headache with retention and getting rid of ZFS snapshots in a timely manner to not fill up the drives needlessly - but it seems to be working.
I just setup the third node (the “analogous” one in specs) which I want to be the active “primary” node and need to copy data over from the other current primary node - I just want to do it intelligently, and then have this node, in its new primary node role, take over the replication of data to the other two nodes.
Would so very, very badly appreciate guidance from those more informed/experienced than me on such topics.
The problem with managing replication outside of PVE is ‘what do you do when you have to move the VM/CT to another node?’ Are you going to move the conf file manually? It’s too much manual work.
Let PVE manage all of the replication. Use Sanoid for stuff that isn’t managed by Proxmox.
Yep that’s also been a concern of mine - I don’t have replication coming from the other nodes as well.
When you say let PVE manage all of the replication - I guess that’s what the main focus of this post is - how? I have those ZFS data pools that are currently just bind-mounted to two CTs, with the VMs mapping to them via NFS (one CT being an NFS server). It’s my understanding that bind-mounted items aren’t supported to be replicated alongside the CTs to which they are attached.
Is there some other, better way to attach them? This is where that italics part comes in - can I just “Add Storage” for these pools and thenadd them via GUI to attach to CTs or VMs, even though they don’t fit those content categories?
Isn’t your use case exactly what Ceph is for?
I think so, but I already have a great deal of data stored on my existing pools - and I wanted the benefits of ZFS. Additionally, it’s my understanding that Ceph isn’t ideal unless you have a number of additional node-to-node direct connections - I don’t have this - insufficient PCIe slots in each node for additional NICs.
But thanks for flagging - in my original post(s) elsewhere I mentioned in the title that I was seeking to avoid Ceph and GlusterFS, and forgot to mention that here. 🙃
That’s the neat part - Ceph can use a full mesh of connections with just a pair of switches and one balance-slb 2-way bond per host. So each host only needs 2 NIC ports (could be on the same NIC, I’m using eno1 and eno2 of my R730’s 4-port LOM), and then you plug each of the two ports into one switch (two total for redundancy, in case a switch goes down for maintenance or crash). You just need to make sure the switches have a path to each other at the top.
Yeah sounds cool, but will likely need to be a project for a successor series of servers one day, given other limitations I have with switches, rack space (and money, haha).
Yeah that’s totally fair. I have nearly a kilowatt of real time power draw these days, Rome was not built in a day.
Hahaha I will not be measuring my power draw, don’t need a reason for my wife to question my absurd tech antics. xD
If you do want to use Ceph you could probably use NICs with multiple ports per NIC.
Additionally you could use switches instead of a fully mesh system.
Full mesh is pretty neat but gets overwhelming very quickly if you have many nodes. With switching you only need two ports per node for your Ceph network.
Gotcha - I’ll keep that in mind for maybe one day down the road. For now I’m limited in PCIe bandwidth lanes on the NICs I have in (10Gb internal networking) and zero open ports on my switches. :(
I think you’re asking too much from ZFS. Ceph, Gluster, or some other form of cluster native filesystem (GFS, OCFS, Lustre, etc) would handle all of the replication/writes atomically in the background instead of having replication run as a post processor on top of an existing storage solution.
You specifically mention a gap window - that gap window is not a bug, it’s a feature of using a replication timer, even if it’s based on an atomic snapshot. The only way to get around that gap is to use different tech. In this case, all of those above options have the ability to replicate data whenever the VM/CT makes a file I/O - and the workload won’t get a write acknowledgement until the replication has completed successfully. As far as the workload is concerned, the write just takes a few extra milliseconds compared to pure local storage (which many workloads don’t actually care about)
I’ve personally been working on a project to convert my lab from ESXi vSAN to PVE+Ceph, and conversions like that (even a simpler one like PVE+ZFS to PVE+Ceph would require the target disk to be wiped at some point in the process.
You could try temporarily storing your data on an external hard drive via USB, or if you can get your workloads into a quiet state or maintenance window, you could use the replication you already have and rebuild the disk (but not the PVE OS itself) one node at a time, and restore/migrate the workload to the new Ceph target as it’s completed.
On paper, (I have not yet personally tested this), you could even take it a step farther: for all of your VMs that connect to the NFS share for their data, you could replace that NFS container (a single point of failure) with the cluster storage engine itself. There’s not a rule I know of that says you can’t. That way, your VM data is directly written to the engine at a lower latency than VM -> NFS -> ZFS/Ceph/etc
Oh I didn’t think the gap window is a bug - I was just acknowledging it, and I’m OK with it.
Definitely some ideas one day for the future but with my current time, architecture, and folks depending on certain services (and my own sanity with the many months I already spent on this), not really looking to re-do anything or wipe drives.
Just want to make the best of my ZFS situation for now - I know it can’t do everything that Ceph and GlusterFS can do.
If the virtual drive for the VM that’s in a ZFS dataset has to keep synchronous with the raw zvol you pass through, you’re going to have a bad time repping them separately and I would just pass in a raw volume that everything, the OS and data, gets stored on, and rep that with syncoid. Personally, unless its some sort of NAS software that absolutely needs a raw ZFS volume to work properly, I just attach virtual drives on a ZFS store and let the VM handle them as ext4. This makes backup with PBS and node to node replication way easier and more reliable. I did it the other way once upon a time, it was a pain in the ass and I didn’t trust my strategies.
As for HA, if you can’t afford to have any gaps from the running VM in a failover, then you have to use a shared storage solution and not repping. I use HA with ZFS replication, but I don’t care if it’s half an hour out of date as nothing is crucial, even Nextcloud syncs.
Hmm, O.K., so you do that part I mentioned in italics? This section under Datacenter, to add those ZFS pools storing data? And then attach them to a VM via GUI?

If I’m understanding correctly, what “Content” selection do you choose for your data files in such pools?
What I think you’re getting at is to add an existing dataset from an existing pool there, then let PM rep it for you.
Here’s what I’d try. Add that pool as above, control-click both VM and container types in the dialog you get. Now go to your VM and add a new virtual drive, with a size that’s bigger than the dataset you want to add by whatever amount you think you will ever want for it. Stop the VM and on the host, edit the vm configuration file to point that new virtual drive at the storagename:dataset of the existing dataset you want to use. Start the VM and see what you get. Then I would expect that proxmox would be able to manage that dataset as if it were a regular one, assuming all the flags match. You will need to have a target store on your other nodes to match the name on the first node for replication to work.
Personally, I would replicate a new dataset from your old one to play with like this before I was certain it did what you want.
Frankly, the easier way to do all this is to copy the data into a regularly made virtual drive on the guest, but this might work fine, too.
Hmm, alright - yeah my other nodes have the same ZFS pools already made.
For adding a virtual drive, you mean going to this section, and choosing “Add: Hard Disk” then selecting whatever ZFS pool I would have added under the prior screenshot, under the highlighted red “Storage” box? Will the VM “see” the data already in that pool if it is attached to it like this?

Sorry for my ignorance - I’m a little confused by the “storagename:dataset” thing you mentioned?
And for another dumb question - when you say “copy the data into a regularly made virtual drive on the guest” - how is this different exactly?
One other thing comes to mind - instead of adding the ZFS pools to the VMs, what if I added them to my CT that runs an NFS server, via Mount Point (GUI) instead of the bind-mount way I currently have? Of course, I would need to add my existing ZFS pools to the Datacenter “Storage” section in the same way as previous discussed (with the weird content categories).
So if you go to /etc/pve/nodes/<nodename>/qemu-server on the PM host, you’ll find the config files for any VMs you made, which you can edit offline. In these files you’ll find all the devices etc you define in the GUI. If you fix the line for the new virtual drive to reflect the storagename:dataset of the existing dataset (from
zfs liston the host), it should attach that dataset via that drive when you boot the guest.Be sure to set the size to reflect at least the existing size of the data in the dataset so you don’t have issues when you bring that drive into the VM as a virtual drive that it’s not addressing the whole dataset because it thinks it ends sooner than it does. You’ll have to fstab that new virtual drive into your guest OS as usual.
As I said, I would highly suggest testing this by repping your dataset to a test dataset before importing it as above just to make sure it works as expected.
And I kinda thought you would be doing this to your NFS server, so just do that same thing but instead of /etc/pve/nodes/<nodename>/qemu-server you want /etc/pve/nodes/<nodename>/lxc for the CT config files. Once you mount the new virt drive in the CT, fix your NFS paths.
Ah, I see - this is effectively the same as the first image I shared, but via shell instead of GUI, right?
For my NFS server CT, my config file is as follows currently, with bind-mounts:
arch: amd64 cores: 2 hostname: bridge memory: 512 mp0: /spynet/NVR,mp=/mnt/NVR,replicate=0,shared=1 mp1: /holocron/Documents,mp=/mnt/Documents,replicate=0,shared=1 mp2: /holocron/Media,mp=/mnt/Media,replicate=0,shared=1 mp3: /holocron/Syncthing,mp=/mnt/Syncthing,replicate=0,shared=1 net0: name=eth0,bridge=vmbr0,firewall=1,gw=192.168.0.1,hwaddr=BC:24:11:62:C2:13,ip=192.168.0.82/24,type=veth onboot: 1 ostype: debian rootfs: ctdata:subvol-101-disk-0,size=8G startup: order=2 swap: 512 lxc.apparmor.profile: unconfined lxc.cgroup2.devices.allow: a lxc.cap.drop:For full context, my list of ZFS pools (yes, I’m a Star Wars nerd):
NAME USED AVAIL REFER MOUNTPOINT holocron 13.1T 7.89T 163K /holocron holocron/Documents 63.7G 7.89T 52.0G /holocron/Documents holocron/Media 12.8T 7.89T 12.8T /holocron/Media holocron/Syncthing 281G 7.89T 153G /holocron/Syncthing rpool 13.0G 202G 104K /rpool rpool/ROOT 12.9G 202G 96K /rpool/ROOT rpool/ROOT/pve-1 12.9G 202G 12.9G / rpool/data 96K 202G 96K /rpool/data rpool/var-lib-vz 104K 202G 104K /var/lib/vz spynet 1.46T 2.05T 96K /spynet spynet/NVR 1.46T 2.05T 1.46T /spynet/NVR virtualizing 1.20T 574G 112K /virtualizing virtualizing/ISOs 620M 574G 620M /virtualizing/ISOs virtualizing/backup 263G 574G 263G /virtualizing/backup virtualizing/ctdata 1.71G 574G 104K /virtualizing/ctdata virtualizing/ctdata/subvol-100-disk-0 1.32G 6.68G 1.32G /virtualizing/ctdata/subvol-100-disk-0 virtualizing/ctdata/subvol-101-disk-0 401M 7.61G 401M /virtualizing/ctdata/subvol-101-disk-0 virtualizing/templates 120M 574G 120M /virtualizing/templates virtualizing/vmdata 958G 574G 96K /virtualizing/vmdata virtualizing/vmdata/vm-200-disk-0 3.09M 574G 88K - virtualizing/vmdata/vm-200-disk-1 462G 964G 72.5G - virtualizing/vmdata/vm-201-disk-0 3.11M 574G 108K - virtualizing/vmdata/vm-201-disk-1 407G 964G 17.2G - virtualizing/vmdata/vm-202-disk-0 3.07M 574G 76K - virtualizing/vmdata/vm-202-disk-1 49.2G 606G 16.7G - virtualizing/vmdata/vm-203-disk-0 3.11M 574G 116K - virtualizing/vmdata/vm-203-disk-1 39.6G 606G 7.11G -So you’re saying to list the relevant four ZFS datasets in there but, instead of as bind-points, as virtual drives (as seen in the “rootfs” line)? Or rather, as “storage backed mount points” from here:
https://pve.proxmox.com/wiki/Linux_Container#_storage_backed_mount_points
Hopefully I’m on the right track!
Add a fresh disk from one of your ZFS backed storages instead of a mountpoint from a directory. When I do that I get a mount like:
mp0: local-zfs:subvol-105-disk-1,mp=/mountpoint,replicate=0,size=8GCan cat me /etc/pve/storage.cfg so I can see where your mp’s are coming from? I’d expect to see them show up as storagename:dataset like mine unless you’re mounting them as directory type.
I read this entire this twice and I still don’t understand what your end goal is. What are you doing that requires all this unnecessary duplication?
Well I guess it’s not too important the end-goal haha. I just have 3 redundant nodes with redundant pools in a cluster. The money’s been spent and the nodes have already been setup. A big part of it was just learning (I work in IT), another part of it is just “active backup” structure of 3 decentralized nodes.


