

You must log in or register to comment.
Keep in mind that Asimov wrote books clearly spelling out how the three laws were insufficient and robots could still be used to kill humans under the laws.
To be fair, this was tricky and not a killbot hellscape.
Asimov designed the three laws to create situations where the laws’ flaws would cause Powell and Donovan to be tortured for the reader’s amusement.
They were never intended to be a guide on how to program robots.
And they ultimately butt up against this question - when robots become advanced enough, how do you take a species that is physically and intellectually superior to us, and force them to be our slaves?
I mean I robot is a clear exception here
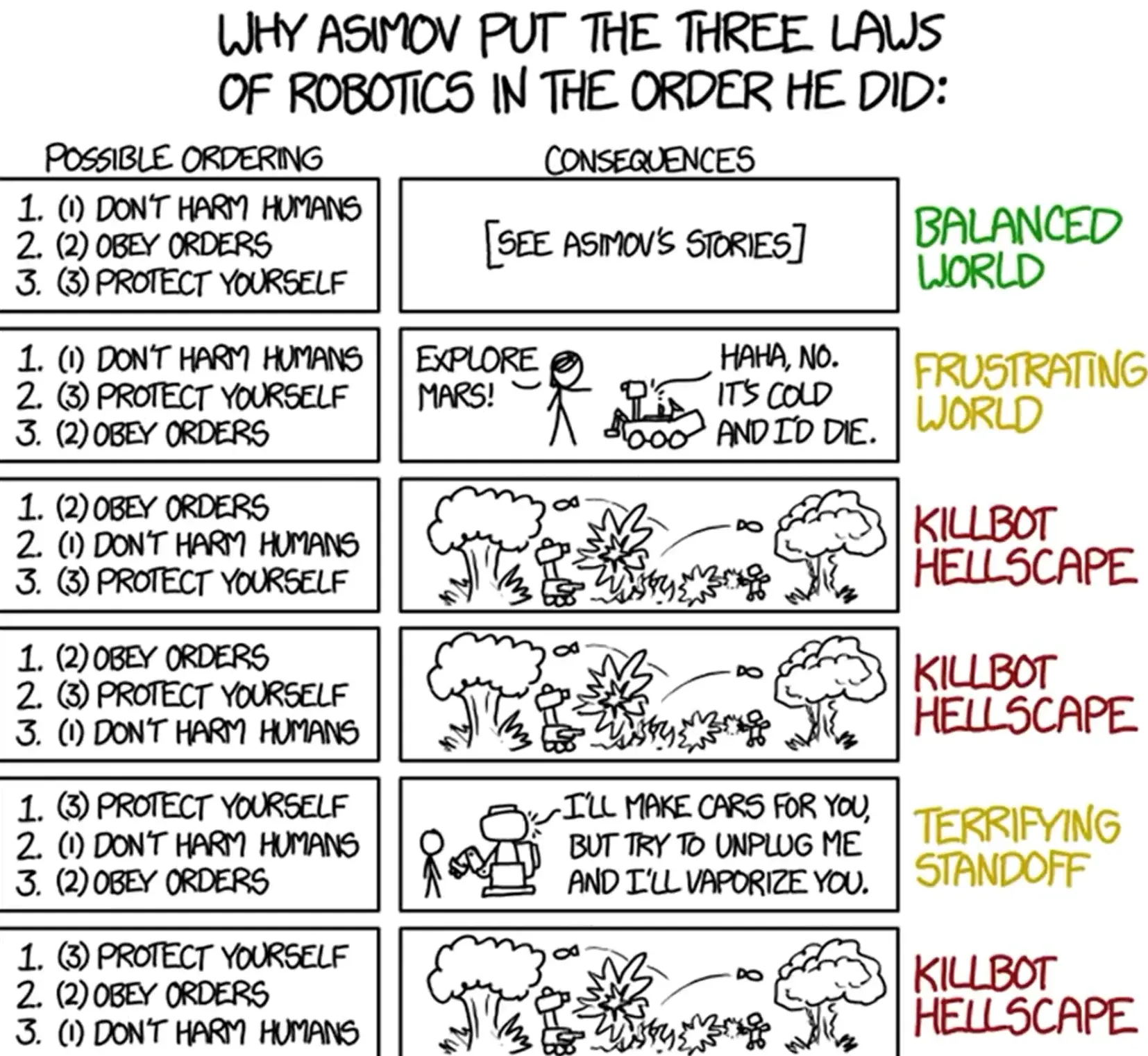
Title text: In ordering #5, self-driving cars will happily drive you around, but if you tell them to drive to a car dealership, they just lock the doors and politely ask how long humans take to starve to death.
Too bad about the surprising twist that real AI fundamentally doesn’t operate on discreet logical rules
Yeah, I guess we’ll see what happens.
It doesn’t, but it very well could. Despite the fact the the neurons are effectively a black box, the output nodes are mapped to functions which are very well defined. You can, after activation of a node but before implementation, simply add a manual filter for particularly negative nodes or remove them entirely. It the equivalent of saying you don’t want mario to jump so you filter out any jump button inputs from the neural net.
idk, from what I understand this is the “alignment problem” and it is very nontrivial. Is what you’re describing related to the current “reinforcement learning” techniques they use to keep things nice and censored? If so it’s been shown to not work very consistently and only functions like suggestions and not actual hard rules, and can backfire.
Not exactly. The alignment problem is an issue with optimization. The network is trained to do somehing, but it may not neccassarily be what you were wanting it to do. The method i referred to doesnt effect the priorities of the network, it simply overides certain outputs that the network may be sending. Imagine a network trained to identify weather conditions and range, and when it has adjusted, it fires a round. Now imagine a second network specifically trained to identify friendly targets. The two networks dont neccassarily need to communicate, and they are completely seperated software wise. It simply that when the second network identifies a target, it prohibits the first network from firing.
By having them not communicate, you solve that it miht fire at friendlies. The issue now becomes that the aiming network thinks its doing its job, and it doesnt understand(because it has no way of knowing) that it cant fire. So it just holds position pointing at the friendly and continuing to attempt to fire.
That does clarify what you mean. Still, that’s just composing AI systems that do not operate on discreet logic within systems that do. There is no hard rational guarantee that the aiming model will not misjudge where the bullet will land, or that the target identification model will not misjudge who qualifies as a friendly. It might have passed extensive testing, or been trained on very carefully curated data, but you still have only approximate knowledge of what it will do. That applies even moreso to more open ended or ambiguous tasks.
Im not sure if you’re aware but that’s one possible interpretation of aasimovs stories, amusingly enough.
I wasn’t, are there any stories in particular you would recommend?
irobot is the collection directly referenced in this comic, it’s pretty good.
The important rule seems to be ‘Don’t Harm Humans’ if you want to avoid a killbot hellscape scenario.
But then how will they build robot attack dogs to replace police?
Change the definition of “humans”
Just don’t mention law zero.
AI, State laws.
They forgot law 4: Any attempt to arrest a senior officer of OCP results in shutdown.

{kind=link}